등록 확인을 위해 길게 늘어선 줄이라니. 너무나 낯선 이 풍경을 어떻게 설명해야 할지 모르겠다. 지난 3년 동안 국내에서 진행했던 세 번의 엔비디아 컨퍼런스에서 볼 수 없던 장면이라서다. 등록대 안에 있던 모든 진행자들이 부지런히 움직였음에도 예정된 시각에서 10분 늦춰 시작한 기조 연설까지 대기 줄을 완전히 사라지게 할 수 없을 만큼 몰린 인파. 당연히 예상된 인원을 모두 처리하지 못한 미숙한 운영에 대해선 변명의 여지가 없고 엔비디아 측도 문제를 개선할 것을 약속할 수밖에 없는 상황이면서도 인공 지능에 뜨거운 관심이 반영된 분위기라는 측면에서 흥미롭기도 했다.
엔비디아 코리아가 11월 7일 삼성동 코엑스 홀에서 개최한 이번 행사의 이름은 ‘엔비디아 AI 컨퍼런스’. 지난 두 번의 ‘GTCxKOREA’와 지난 해 ‘딥 러닝 데이’에 이어 엔비디아의 GPU 기술을 기반으로 한 인공 지능 관련 기술을 설명하는 자리지만, 이야기는 언제나 비용 대비 효과가 좋은 엔비디아의 하드웨어로 그 일을 빠르게 잘 끝낼 수 있다는 것으로 귀결된다.

엔비디아 코리아가 올해 행사의 이름을 AI 컨퍼런스로 이름을 바꾸긴 했어도 종전 GTCxKOREA나 딥 러닝 데이 등 지난 세 번의 컨퍼런스와 비슷한 이야기 구조를 갖고 있다. 엔비디아가 해마다 개최하고 있는 GPU 기술 컨퍼런스인 GTC(GPU Technology Conference)에서 발표한 GPU 기술과 동향, 제품을 자세히 설명하고 이를 적용한 사례에 대한 이야기는 크게 다르진 않은 것이다. 다만 시간이 지날 수록 GTC의 기본 골격에 새로 추가된 기술이나 사례, 발표 국가마다 협업의 결과를 추가하므로 GTC와 모든 내용이 동일한 것은 아니다.
하지만 엔비디아 컨퍼런스의 문을 여는 말은 거의 비슷하다. 젠슨 황 엔비디아 CEO가 그랬던 것처럼 AI 컨퍼런스의 기조 연설을 책임진 엔비디아 마크 해밀턴 부사장도 지난 50년 동안 IT 업계의 불문율처럼 여겨지던 무어의 법칙을 더 이상 실행하기 어려워진 CPU를 대신해 GPU가 컴퓨팅의 수요 곡선에 제대로 대응하고 있다는 사실을 상기시킨다.
그런데 이 말은 듣기에 따라서 CPU보다 GPU의 처리 능력이 더 낫다는 점을 강조하려는 것처럼 보이지만, 실제로는 그런 의미를 담고 있는 게 아니다. 컴퓨팅 환경의 일부 변화를 설명하기 위해 꺼낼 수밖에 없는 불가피한 도입일 뿐이다. 물론 GPU는 인공 지능 시장이 확대되면서 GPU의 역할이 늘었고 중요성이 더 늘어난 것은 사실이다. 다만 왜 많은 연구자들이 인공 지능에 주목했고 또한 GPU를 필요로 했는가에 대한 근본적인 질문이 들어 있다.
엔비디아가 말하고 싶은 점은 ‘데이터’를 처리하는 환경의 변화다. 특히 CPU보다 GPU에 주목한 배경을 주목한 것이다. 종전까지 데이터를 처리해왔던 것은 CPU다. CPU는 인간이 짠 프로그램의 규칙을 따라 처리했고, 처리할 데이터가 늘어남에 따라 성능을 높여왔으며, 인간은 개선된 CPU에 맞춰 프로그램을 개선했다. 문제는 네트워크가 발전하고 수많은 센서와 디지털 장치들이 늘면서 엄청나게 데이터가 쌓이기 시작했다는 것이다. 이제 전통적인 조건문 프로그래밍을 온 인류가 배워도 눈깜짝할 사이에 쌓인 빅데이터를 처리할 만한 코드를 작성할 수 없는 상황까지 왔다. 기존 방식대로 프로그램을 만들면 세상의 데이터를 처리할 수 없는 지경에 이른 것이다.

결국 데이터를 처리할 새로운 방식의 프로그래밍이 필요했다. 컴퓨터 또는 데이터 사이언티스트나 개발자들의 전통적인 프로그래밍에 의존하지 않는 방법은 인간의 개입 없이 데이터를 처리하는 것이다. 사람을 대신해 계속 쌓이는 데이터를 처리할 프로그래밍을 찾아 내는 것. 그 프로그램을 만드는 과정 중 하나가 바로 신경망 알고리즘을 통한 딥 러닝이다. 입력된 데이터가 복잡하게 얽힌 여러 논리 계층을 거치는 훈련(행렬 연산)을 반복하면서 마침내 결론을 끌어낼 수 있게 되면 이제 그 데이터를 처리할 수 있는 하나의 소프트웨어가 만들어진다. 전통적인 프로그램 작성법을 대신해 소프트웨어 스스로 데이터를 분석하고 판별하는 인공 지능 소프트웨어를 작성하는 셈이다.
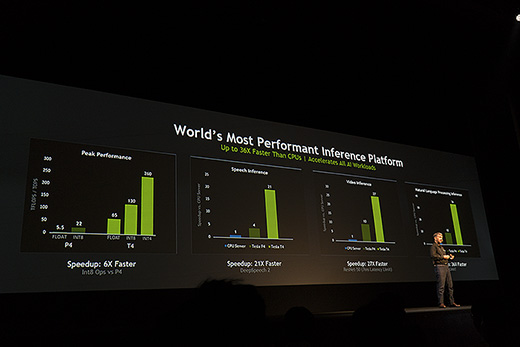
다만 하나의 결과를 얻기까지 걸리는 시간이 문제다. 사람이 짠 프로그램대로 처리하면 빠르지만, 기계 스스로 프로그램을 하려면 복잡한 심화 신경망 안에서 행렬 연산으로 처리하는 여러 알고리즘을 거쳐야 하는데, 이에 효율적이고 강력한 처리 장치가 필요하다. 트랜지스터를 늘리고 성능을 끌어올려 최적화된 프로그램을 처리하는 데 효율성을 높여온 CPU로는 감당할 수 없었지만, 그래픽 처리를 위해 부동소수점을 효율적으로 처리할 수 있도록 병렬 연산 구조를 갖춘 GPU가 딥 러닝을 가속할 수 있음을 확인한 이후 인공 지능 분야가 빠르게 발전하기 시작한 것이다.

현재 나와 있는 GPU나 AI 칩은 딥 러닝을 가속함으로써 데이터를 처리할 수 있는 더 많은 인공 지능 소프트웨어들을 만들어내도록 기여한다. GPU나 AI 칩이 딥 러닝 알고리즘 안에서 일어나는 행렬 연산을 더욱 빠르고 효율적으로 처리할 수 있도록 꾸준하게 발전하면서 서로 다른 언어를 해석하고 음성으로 명령을 하거나 사물을 인식할 뿐만 아니라 자동차를 운전하고 환자의 상태를 진단하며, 사회 안전망을 강화하는 등 일상을 조금씩 바꿔나가고 있는 상황이다.
물론 딥 러닝을 거쳐 만들어진 인공 지능 소프트웨어가 실제 환경에서 데이터를 추론하기 위해서는 이에 걸맞은 최적화도 필요하다. 지금 스마트폰이나 스피커에 추론을 더욱 최적화할 수 있는 AI 코어를 포함하는 것도 그런 이유다. 때문에 엔비디아는 인공 지능 프로그램을 만드는 딥 러닝 부문과 실행 중인 인공 지능 프로그램의 추론을 가속화하는 모든 곳에 존재하기 위한 제품을 만든다. 그것은 서버에 들어가는 크기일 수도 있고, 책상 옆에 두는 워크스테이션일 수도 있고, 자동차에 싣는 기판일 수도 있고, 손바닥 만한 카드일 수도 있다. 새로운 튜링 아키텍처 기반의 PC용 그래픽 카드도 더 이상 예외가 아니다. 결과적으로 엔비디아는 인공 지능의 시작부터 끝까지 있는 회사가 됐다. 엔비디아가 이럴 줄 알았냐고? 그 누구도 몰랐다. 심지어 엔비디아 CEO인 젠슨 황 조차도 이렇게 될 줄 몰랐다 하지 않던가.
Be First to Comment