실시간 광선 추적 렌더링을 게임에서 경험할 수 있는 엔비디아 지포스 RTX 그래픽 카드는 분명 게이밍 그래픽에 대한 환상을 현실로 이룰 수 있는 중요한 변곡점이었지만, 그 경험을 위해 이용자에게 요구한 지출의 범위는 너무나 가혹한 것이었다. 비록 빛 효과로 실제 같은 게이밍 그래픽을 위해서 튜링 SM 뿐만 아니라 실시간 빛 계산에 쓰는 RT 코어, 그리고 기계 학습으로 렌더링을 추론하는 텐서 코어를 넣어 가장 진화된 GPU를 내놓았음에도, 아직 준비되지 않은 레이 트레이싱 게이밍 환경과 앞날에 대한 불확실성이 많은 게이머들을 머뭇거리게 했다.
그런데 여기에 또 다른 이유를 하나 더 붙이고 싶은 이들이 있을 것이다. 지포스 RTX 출시 이후 마치 그림자처럼 따라 다녔던 새로운 지포스 GTX에 대한 소문에 대한 희망을 품었던 이들 말이다. 특히 GTX 11 시리즈에 대한 소문은 단순한 풍문으로 그치지 않고 그동안 실제처럼 보일 법한 여러 벤치마크 결과가 공유되며 소문을 부풀렸다. 물론 그 데이터의 진위는 확인할 수 없지만, 적어도 한 가지는 확실해졌다. 엔비디아가 지포스 GTX 1660 Ti를 공식 발표함으로써 기다림을 헛되게 만들지 않았다는 점이다.

엔비디아 지포스 GTX 1660 Ti는 RTX와 전혀 다른 방향의 그래픽 카드다. 빛 추적 렌더링의 효율성을 강조했던 RTX와 다르게 GTX 1660 Ti는 튜링 아키텍처의 연산 능력에 초점을 맞추고 있다. 때문에 RTX 그래픽 카드에 들어간 RT 코어는 물론 추론 연산을 위한 텐서 코어까지 제외했다. 텐서 코어의 제외는 기계 학습 기반 샘플링(DLSS)도 작동하지 않는 것을 뜻하는데, 엔비디아는 빛 추적 렌더링 및 DLSS를 RTX 플랫폼에서만 지원한다고 강조했다.
결국 GTX 1660 Ti는 기존 파이프라인에 의존하는 연산의 처리 능력으로 승부를 걸 수밖에 없는 상황이다. 물론 GTX 1660 Ti도 튜링 아키텍처다. GTX 1660 Ti에 실린 GPU는 TU116으로 모델 넘버를 갖는다. 비록 RT 코어와 텐서 코어가 없어도 기존 처리 장치들의 구조가 바뀌었기 때문에 그만한 성능 향상을 경험할 수 있다는 것이 엔비디아의 이야기다.

기존 GTX 10 시리즈의 파스칼과 대비해 GTX 16 시리즈에 실린 튜링 아키텍처의 차이는 하나의 연산 장치에서 부동소수점과 정수 연산을 분리하기 않고 동시에 실행하는 구조로 바꿨다는 점이다. 기존 처리 구조는 부동 소수점의 연산이 많은 부동 소수점을 동시에 더 빨리 처리하는 구조를 갖췄지만, 점점 더 많은 게임에서 정수 연산이 늘어남에 따라 이를 처리할 때 순차적인 처리로 인해 처리 능력이 저하되는 것을 피할 수 있는 구조로 바꿨다.
엔비디아 GPU는 최소 처리 장치인 쿠다(Compute Unified Device Architecture) 코어라고 부르는 스트리밍 프로세서에서 데이터를 처리한다. 쿠다 코어마다 들어오는 명령과 데이터에 따라 산술 및 논리를 처리하고 부동소수점을 연산한다. 하지만 매우 작은 단위의 쿠다 코어를 효율적으로 다루기 위해 지난 파스칼 아키텍처는 일정 개수의 코어와 배정도 유닛(DPU), 특수 기능 유닛(SFU), 공유 캐시 및 L1 캐시, 명령어 캐시 및 버퍼, 레지스터를 묶어 SM(Streaming Multi Processor)을 구성하고 이를 TPC(Texture Processing Cluster) 안에 담았다. 파스칼 아키텍처는 TPC 1개당 하나의 SM만 담고 있었고, 파스칼 SM은 128개의 코어로 구성됐다.

기존 파스칼 아키텍처는 쿠다 코어를 묶고 있는 SM을 늘릴 수록 더 나은 성능을 낼 수 있지만, 한편으로 쿠다 코어를 늘릴 수록 더 큰 공간을 차지하고 더 많은 전력을 요구한다. 때문에 GTX 16 시리즈와 RTX의 튜링 SM은 기존 파스칼 SM의 구조를 바꿨다. 각 SM당 64개의 쿠다 코어만 담고 TPC 당 두 개의 SM을 넣은 것이다.
하지만 SM을 단순히 2개로 분리해 TPC를 구성한 것만으로 성능이 좋아진 것은 아니다. 쿠다 코어가 많을 수록 처리 성능이 좋아지는 기존의 상식에 따르면 단순한 분리만으로 성능이 더 좋아진다고 말할 수는 없기 때문이다. 엔비디아가 튜링 SM에서 신경 쓴 부분은 기존 코어와 달리 정수형 데이터를 병렬로 처리할 수 있게 INT 코어를 기존 코어와 같은 수만큼 넣고 SM을 분리한 만큼 레지스터와 L1, 공유 캐시 크기 및 TPC에 전달되는 대역폭까지 모두 2배씩 늘렸다.
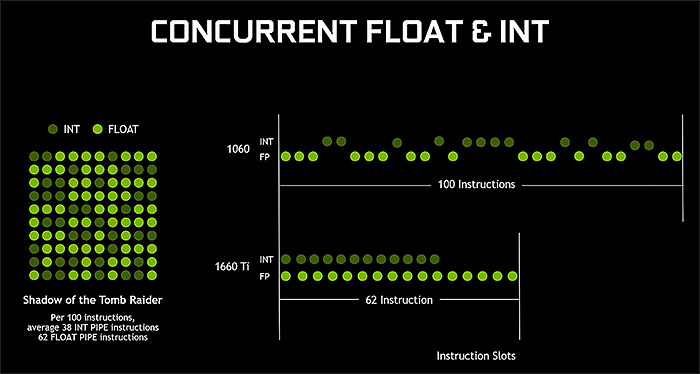
이러한 구조 변경은 오늘 날 게임들의 정수형 처리가 의외로 많아지면서 반영된 것이다. 과거 게임보다 게임내 효과가 다양해 지면서 컴퓨팅 연산을 많이 하는데, 지금처럼 하나의 코어로 명령어와 데이터를 처리하는 현재의 방식은 효율성이 떨어지기 때문이다. 예를 들어 100번의 부동 소수점을 연산하는 동안 50번의 정수형 연산을 처리할 경우를 보자. 기존 파스칼 SM은 쿠다 코어에서 이를 모두 처리하려면 150번 걸리지만, 정수형 코어가 함께 작동하면 쿠다코어에서 100번의 부동 소수점을 처리하는 시간 안에 50번의 정수형 처리도 끝낼 수 있어 그만큼 시간을 단축할 수 있어 같은 시간의 처리 효율이 높아진다.
엔비디아는 이 같은 처리 구조의 변경으로 파스칼 아키텍처보다 적은 쿠다 코어를 가진 튜링 아키텍처가 더 나은 성능을 얻을 수 있음을 뒷받침하는 결과를 공개했다. 기존 파스칼 기반 GTX 1060과 튜링 기반 GTX 1660 Ti에서 실행한 <울펜슈타인 2>, <쉐도 오브 더 툼레이더>, <콜 오브 듀티 : 블랙 옵스>에서 게임 프레임을 비교한 결과 GTX 1660 Ti에서 40~50% 더 많은 프레임 증가를 확인한 것이다. 클럭 당 명령어 처리는 1.5배 더 늘었고, 동일 전력 대비 처리 성능에서 1.4배 더 향상된 결과는 파스칼 아키텍처보다 효율적이라는 것을 보여준 셈이다.

이처럼 기존의 게임을 가속하기 위해 효율적인 처리 구조를 갖춘 GTX 1660 Ti는 먼저 출시된 지포스 RTX 플랫폼과 동일한 성능이나 기능을 갖는 것은 아니다. 앞서 소개한 대로 빛 추적 렌더링을 효율성을 높이는 RT 코어 뿐만 아니라 추론을 위한 텐서 코어의 제외로 기계 학습 기반 렌더링도 작동하지 않는다. 원본 이미지를 분석해 부분적으로 쉐이딩 범위를 줄이는 반응형 쉐이딩(Adaptive Shading)이라는 기법이 작동하지만, 그렇다고 DLSS처럼 더 나은 렌더링 품질로 개선하는 것은 아니다.
그래도 360도 고화질 이미지를 저장하는 안셀이나 이펙트를 넣는 프리스타일, 게임 방송의 품질을 높일 수 있도록 높은 비트레이트의 실시간 인코딩은 GTX 1660 Ti에서도 빠짐 없이 지원한다. RTX 플랫폼에서 거의 기본으로 싣고 있는 버추얼링크 포트는 그래픽 카드 제조사마다 선택 사항으로 담는다. 열설계전력(TDP)는 120W. 6GB의 그래픽 램에 따라 제한된 해상도와 품질의 게임을 즐길 수 있는 지포스 GTX 1660 Ti는 275달러부터 시작한다. (물론 실제 제품 가격은 이보다 더 높다.)

엔비디아 지포스 GTX 1660 Ti는 단순하게 보면 실시간 추적을 위한 기술적 요소를 배제한 것처럼 보여도 튜링 아키텍처의 진짜 실력을 가늠할 수 있는 그래픽 카드다. 더구나 빛 효과에 대한 주관적인 만족보다 객관적 수치로 확인할 수 있는 향상된 성능에 대한 단순한 접근법은 아직 여건이 준비되지 않은 게이밍 환경에 투자를 꺼리던 게이머들도 이해하기 쉽다. 이런 이유로 GTX 1660 Ti가 게이머들을 설득할 수 있을 지 좀더 지켜봐야겠지만, 지포스 RTX에 대한 고집을 꺾고 지금이라도 선택의 폭을 넓히는 전략적 결정을 너무 늦게 하지 않은 것만은 다행일지도 모른다.
Be First to Comment