
저는 어제 이세돌 프로에게 한 가지를 물었습니다. 어떻게 경우마다 수를 결정하느냐고. 이세돌 프로가 그러더군요. “바둑은 수가 너무 많아 직관에 의존해 결정한다”고. 그래요. 바둑은 직관력이 중요한 게임입니다.
우리는 인공 지능이 바둑을 두는 데 요구되는 계산력과 직관력을 기르는 데 힘썼죠. 바둑판의 패턴 인식이나 계획을 세우는 수립 능력도 물론이고요. 하지만 쉽지 않았어요. 워낙 경우의 수가 많아 무작위 대입 방법으로는 두기 어렵다는 것을 알았죠. 그 수가 10의 170승이나 됐으니까요. 바둑판의 탐색 공간이 너무 거대해서 이기고 지는가에 대한 평가 함수를 만들기 어려웠어요.
때문에 우리는 두 개의 신경망 트레이닝을 시도했습니다. 10만 건의 전문가 데이터를 내려 받아 인간의 계획을 모방한 정책망을 숙달시켰죠. 단순한 모방보다 더 나은 게임을 원했던 우리는 이에 대치되는 또 다른 두 번째 정책망을 만들어 서로 경기를 치르도록 했지요. 정책망 스스로 3천만번의 경기를 치른 이후 이기고 지는 것을 판단할 수 있는 가치망을 만들 수 있었어요. 이런 시기를 거치며 수개월 후 우리는 3개의 신경망을 만들었습니다. 그리고 통계에 따라 가장 좋은 수로 결정 범위를 좁히는 정책망과 현재 놓은 돌의 승패를 평가하는 가치망을 가진 알파고를 선보일 수 있게 됐어요.
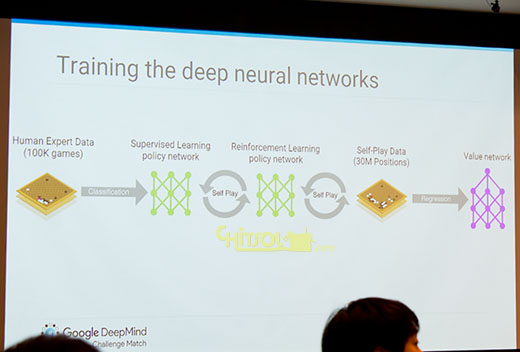
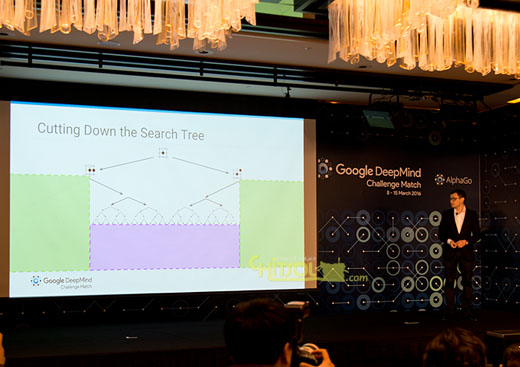
그런데 많은 이들은 알파고가 엄청난 컴퓨팅 파워를 동원해 바둑에서 모든 경우의 수를 검토한 뒤 바둑을 두는 것이라고 생각하는데요. 전혀 그렇지 않습니다. 아무리 컴퓨팅 파워가 좋아도 모든 변수를 다 파악하는 데 시간이 너무 오래 걸리거든요. 때문에 알파고는 둬야 할 수를 좁히고 그 수에 대한 평가를 합니다. 프로그래머의 개입 없이 말이죠. 돌을 둬야 할 수를 좁히는 것, 이 부분이 사람의 직관과 닮아가는 부분입니다. 돌을 어떤 방향으로 놓을 지, 그 돌로 인한 승패의 영향을 미칠 것인지 범위를 좁히고 그 안에서 무작위 경우의 수를 넣어 답을 찾아냅니다.
지난 해 알파고는 크레이지 스톤, 젠 등 경쟁 중인 인공 지능과 495번의 대결 중 494번을 이겼고, 4점 접바둑을 두었을 때도 75%의 승률을 기록한 바 있습니다. 하지만 여기서 실험을 멈추지 않았죠. 이후 유럽 챔피언 판 후이 2단과 호선으로 승부를 벌여 5전 전승을 냈다는 소식은 지난 번에 전했습니다. 이는 업계 예상보다 10년을 앞당긴 소식이었어요.

물론 지금의 알파고는 판 후이 2단과 승부를 벌일 때의 그 알파고와 또 다릅니다. 아, 더 좋은 성능의 하드웨어를 보강했다는 의미가 아니에요. 이세돌 9단과 승부를 펼칠 하드웨어는 판 후이 2단 때와 같습니다. 단지 알고리즘을 개선했을 뿐이에요. 물론 프로그래머가 직접 개입한 것이 아니라 인공 지능 스스로 말이죠. 컴퓨팅 파워를 더하면 오히려 안좋은 결과가 나올 수 있는 아이러니한 문제 때문에 그 부분은 보강하지 않았습니다. 또한 알파고는 싱글 매치 버전과 분산 버전이 있습니다. 지난 대국과 형평성을 유지하기로 한 이상 시스템 조건은 그 때와 똑같이 분산 버전을 씁니다.
또한 이세돌 9단과 대국을 앞두고 특수 훈련을 시도한 적은 없습니다. 물론 지난해 10월 버전과 이번 버전의 차이가 없는 것은 아니에요. 양질의 자가 학습 데이터를 통해 성장했으니까요. 앞서 말한 대로 직관은 바둑에서 중요한 부분입니다. 직관을 모방할 수 있는지 테스트했고, 인간 전문가를 모방할 수 있다는 결론을 얻었죠. 그것을 이번 대국에서 확인할 수 있을 겁니다.
아, 인공 지능이 발전해 사람의 지능에 가까워질 수록 인류의 미래에 위협이 될 것이라는 이야기는 많이 들었습니다. 제 견해는 인공 지능은 아주 강력한 툴이 될 것이라는 데 이견은 없습니다. 단지 중립적인 기술을 인류가 어떻게 쓰느냐의 문제에요. 이 기술을 책임감을 갖고 윤리적으로 사회가 이용해야 합니다. 구글과 딥마인드는 이 부분에 더 관심을 갖고 있으며 인류에게 유익한 기회를 만들어야 하지요. 수많은 연구와 도전 과제를 극복해야 인간 수준의 인공 지능이 탄생할 겁니다. 지금의 인공 지능은 그냥 게임을 하는 수준일 뿐이에요. 아직 수십년은 더 기다려야 합니다.
단지 우리는 지금 인공 지능을 게임 이상의 영역에 활용하고 싶을 뿐입니다. 지능을 분석하고 인류의 문제 해결에 쓰고 싶은 것이죠. 의료나 로보틱스, 스마트 애플리케이션 등에서 인공 지능이 활용될 수 있기를 바랍니다. 이처럼 인류가 직면한 문제에 대해 알파고가 아주 강력하면서 유연하게 대응할 수 있기를 바랄 뿐이죠. 이는 이번 대국에 상관 없이 인간의 창의성을 증명하는 일입니다. 알파고도 결국 현명한 인간들이 만든 것이니까요.
* 이 글은 8일 오전 서울 포시즌 호텔에서 가진 구글 딥마인드 챌린지 매치에서 알파고를 만든 딥마인드 창업자 데미스 하사비스의 이야기를 정리한 것입니다.
연관글
Be First to Comment