“어? 저 배우 누구였더라?”
영화나 드라마를 보다보면 얼굴은 낯익지만, 이름이 가물가물할 때가 있다. 다른 영화에서도 본 듯 한데 그가 출현한 영화 제목이 머리에 떠오르지 않을 때도 있을 것이다. 그럴 때마다 잽싸게 그 자리를 채우는 ‘나이 들어간다’는 서글픈 퍼즐 조각에 한숨을 내뱉을 뿐이다. ‘대체 그게 뭐라고 나이까지…’라고 푸념한들 무슨 소용이랴.
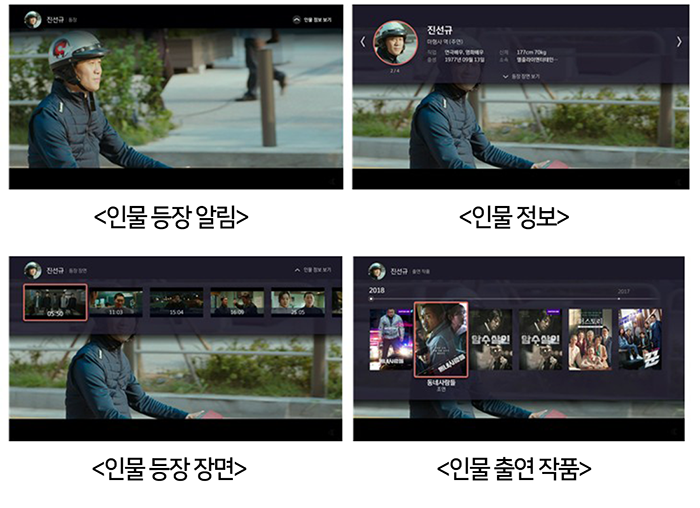
그나마 다행인 점은 리모컨 버튼만 한 번 누르면 이제 ‘나이’라는 단어가 떠오르기 전에 잠시 실종된 뇌세포를 되돌려놓는 시대에 들어섰다는 있다는 점이다. 리모콘으로 인공 지능이 알듯말듯했던 그 이름을 대신 찾아내기 때문이다. 영상 속 배우가 누구인지 알아채고 어떤 영화에서 봤는지 등 학습을 마친 인공 지능은 벌써 SKB 인사이드 같은 서비스에 접목되어 TV 앞 시청자의 기억을 보완하고 있다. 지금까지 브라우저를 띄우고 영화 정보를 찾는 수동적인 검색의 시대를 인공 지능이 대체해 가고 있는 것이다.
인공 지능도 처음부터 아는 것은 아니다
우리는 스마트폰에 있는 앱이나 서비스로 사람이나 사물을 알아채는 인공 지능을 어렵지 않게 쓸 수 있는 시대에 와 있다. 그런데 이러한 인공 지능과 사람 사이에 의외로 비슷한 면이 하나 있다. 낯선 사람이나 사물을 처음부터 단번에 알아 채지는 못한다는 점이다.
예를 들어 낯선 이름의 신인 케이팝 그룹이 어느 날 방송 프로그램에 등장한다고 가정해 보자. 현란한 안무를 곁들여 노래하는 4분 안팎의 시간 동안 동안 멤버의 얼굴과 이름을 단번에 기억하는 이들이 몇이나 될까? 아마 거의 없을 것이다. 그런데 우리는 시간이 지날 수록 그들의 얼굴과 이름을 알게 된다. 음악이나 예능 방송에서 활약하는 모습을 보기면서, 또는 인터넷에 뜨는 콘텐츠와 뉴스 등 다양한 자료를 통해 그들을 알아가는 것이다.
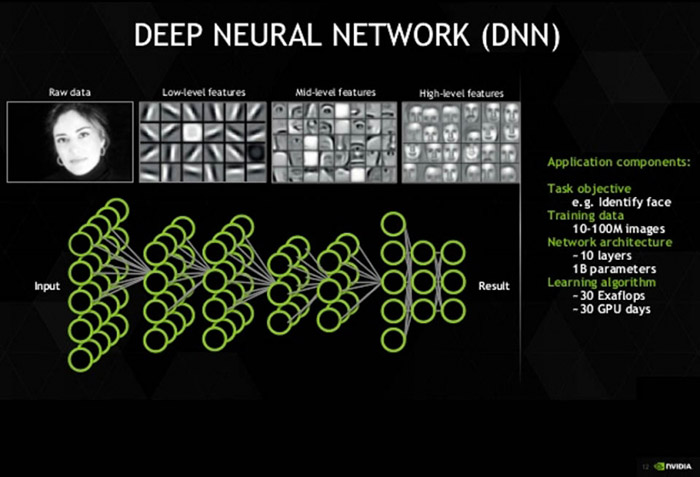
인공 지능도 이와 다르지 않다. 인공 지능 역시 사람처럼 처음 보는 낯선 것을 알지 못한다. 인공 지능은 프로그래머가 처음부터 끝까지 모든 코드를 짜는 게 아니라 그저 몇 줄 코드 만으로 시작할 뿐, 첫 시작에선 아무 생각이 없는 백지 상태에 가깝다. 하지만 사람과 마찬 가지로 수많은 데이터를 학습하며 인식 능력을 높여간다.
다른 점이라면 인공 지능은 미리 주어진 결과를 찾는 과정을 거쳐 코드를 완성한다는 점이다. 이를 테면 A라는 사람이나 사물에 대한 이미지를 먼저 주고 수많은 이미지 데이터에서 A를 찾아내는 공식은 인공 지능이 찾아 내는 식이다. 이를 위해 인공 지능은 뇌의 체계를 본딴 신경망에 투입된 이미지 데이터를 세밀하게 나눠서 연산하면서 결과와 맞아 떨어지는 코드를 만들 때까지 기계 학습을 반복한다. 이 과정에서 인공 지능은 프로그래머 대신 스스로 프로그래밍을 하는 셈이다.

이렇게 이미지 인식 훈련을 마친 인공 지능은 그 이후 다양한 유형의 서비스에서 활용되고 있다. 카메라로 비추는 사물이 무엇인지 파악한 뒤 상품 이름이나 성분을 보여주거나 차선을 자유롭게 넘나 들며 안전하게 목적지까지 달리는 자율 주행 자동차에 응용 되기도 하고, 영화 속에 나온 배우를 알아보고 관련 정보를 찾아 보여주는 등 이미 우리 일상에 가까이서 쓰이는 중이다.
인간 중심적 관점으로 이동 중인 인공 지능
지금 이 순간에서 더 나은 인공 지능을 위해서 수많은 이미지 데이터를 통해 사물이나 사람, 환경을 이해하는 기계 학습은 쉼없이 이뤄지고 있다. 하지만 단순히 사물이나 사람을 인식하는 것에서 끝나는 것은 아니다. 이제는 이미지나 영상에 담긴 맥락을 스스로 풀어내는 단계로 넘어가고 있다.
여행지에서 찍은 셀카 사진을 예로 들어보자. 그 사진에는 당연히 사람이 보일 뿐만 아니라, 하늘이나 여행지의 유명한 상징물도 있을 것이다. 이미 학습된 인공 지능은 능력을 발휘해 사진 속에 있는 사람이나 하늘, 상징물을 가려낸 뒤 그것이 무엇인지 알려준다.
하지만 사진 속의 단편적인 정보를 잘 보여주는 인공 지능 만으로는 충분하다고 느끼는 이용자는 별로 없다. 그런 정도는 인공 지능의 능력을 빌리지 않아도 되니까. 때문에 지금 인공 지능은 사진에 담긴 맥락을 이해하는 학습을 하고 있다. 단편적으로 피사체를 인식하는 게 아니라 사진 전체의 모습을 한 줄 문장으로 써내는 일이다.
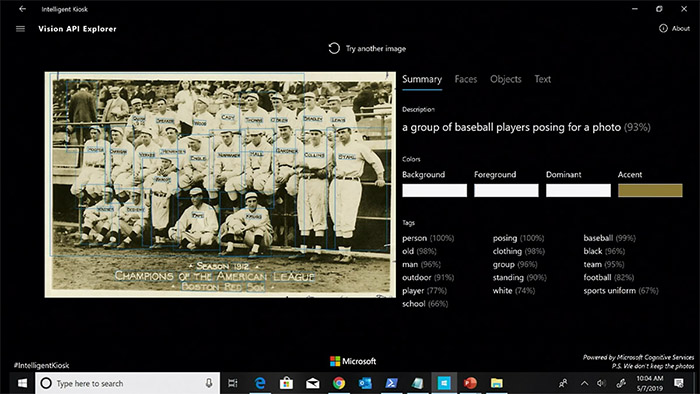
만약 특정한 장소에서 웃는 사람의 모습으로 찍은 사진을 주면 인공 지능은 ‘노을을 배경으로 에펠탑 앞에서 40대의 남성이 즐거운 표정으로 찍은 사진’이라는 자막을 붙인다. 우리가 사진을 볼 때는 몰랐던 남성의 나이를 짐작하고 감정까지 읽어 이를 우리가 이해할 수 있는 문장으로 정리할 수 있는 수준까지 와 있다. MWC나 CES 같은 대규모 전시회에서 지나가는 참관객의 얼굴로 나이와 감정을 분석하는 인공 지능은 꽤 많은 인기를 모았는데, 실제로 이를 활용하는 단계로 넘어가고 있다.
이러한 맥락의 이해가 중요한 것은 반대로 그 조건에 해당하는 정보를 찾기 위해서다. SKB가 인사이드에서 향후 ‘좋아하는 배우의 키스 씬’, ‘영화 속 명장면’처럼 상당히 어려워 보이는 요구에도 해당 장면으로 곧바로 이동하는 기능을 넣는다고 설명했는데, 인공 지능이 이용자의 요구에 맞는 장면을 찾아내려면 상황을 이해하는 능력을 갖춰야만 하는 것이다.
이는 결국 인공 지능이 좀더 인간 중심적 관점으로 실행되어야만 더욱 유연한 상호 작용을 할 수 있다는 것을 뜻한다. 때문에 수많은 ICT 기업들이 인지 AI(Cognitive AI)를 위해 많은 노력을 기울이는 것도 이런 이유다. 어쨌든 우리는 곧 다양한 결과를 경험하게 되겠지만, 적어도 사람과 인공 지능이 서로에게 훨씬 쉽게 적응할 것이라는 점은 분명하다.
덧붙임 #
이 글은 SK브로드밴드에 기고한 글의 원문으로 글이나 이미지가 일부 다를 수 있습니다.
Be First to Comment