
문득 퀄컴이 급했을 지도 모른다는 생각이 든다. 지난 1월 발표한 고성능 모바일 프로세서인 퀄컴 스냅드래곤 835의 후속 제품을 새 달력을 걸기도 전에 또 공개했기 때문이다. 12월 6일 퀄컴 테크놀로지 서밋 행사에서 스냅드래곤 845의 발표라는 보기 드문 광경을 연출한 배경이 무엇이던 간에 조기 등판한 차기 고성능 모바일 프로세서는 돌아볼 구석이 많아 보인다.
차기 모바일 프로세서로서 스냅드래곤 845는 스냅드래곤 835 대비 나아진 정도만 찾아서 말하기는 어려울 정도다. 그만큼 처리 성능 뿐만 아니라 보안이나 무선 전송 성능, 인공 지능과 시각 기술 등 상당 부분 달라졌다. 독자 기술에 대한 집착을 버리고 ARM 코어텍스 A75와 A55를 변형한 크라이오 385 골드와 실버 코어를 4개씩 넣은 옥타 코어 CPU는 높은 코어 클럭(골드 2.8GHz, 실버 1.8GHz)에 새로운 L3 캐시 구조의 채택, 처리 상황에 따라 모든 빅리틀 코어를 동시에 켜는 ARM 다이나믹(ARM DynamiQ) 도입, 대역폭이 넓어진 메모리를 통해 성능을 높였다. 4K와 시각 현실의 시각적 처리 능력을 높인 GPU 아드레노 630, 기가 비트 이상의 전송 성능을 내는 X20 LTE 모뎀, 보안을 강화한 시큐리티 프로세싱 유닛 등 이 프로세서는 이전 세대와 많은 부분에서 다른 점이 눈에 띈다.
하지만 이러한 성능 향상을 위한 구조의 변경보다 기대했던 것은 인공 지능에 대한 해법, 그리고 이 프로세서에서 새롭게 기대할 만한 의외 무엇일 지도 모르겠다. 다행히 스냅드래곤 845를 발표한 퀄컴은 그 두 가지에 대한 답을 모두 내놨다고 본다. 다만 일반적인 접근과는 다른 방식이어서 흥미롭다. 인공 지능을 위한 추론 처리를 DSP에서, 가상 현실의 진화에 필요한 그래픽 처리 기술을 도입한 게 그렇다. 이 두 가지만 들여다 봤는데도 스냅드래곤 845는 충분히 흥미로운 프로세서라는 것을 알 수 있다.

DSP로 기계 학습을 하다
스냅드래곤 845은 인공 지능 관련 코어는 별도로 존재하지 않는다. 퀄컴은 많은 논쟁이 있는 전용 하드웨어 가속화는 매우 신중한 선택이 필요하고, 올바른 자리에 배치하지 않으면 실리콘을 낭비하게 될 것이라고 질의응답 세션에서 밝힌 만큼 확실히 전용 코어는 들어가지 않는다.
그렇다 해도 스냅드래곤 845가 인공 지능 관련 기능을 적용하는 데 필요한 능력 자체가 없는 것은 아니다. 퀄컴은 디지털신호처리장치(DSP)인 헥사곤 685(Hexagon 685) 코어가 기계 학습 명령을 처리한다고 말한다. 실시간으로 변환되는 영상이나 사진, 소리 같은 아닐로그 세계의 연속된 신호를 측정하고 걸러내 압축된 디지털 신호로 바꾸는 DSP를 여러 인공 지능 관련 처리에 필요한 작업까지 맡기겠다는 것이다.
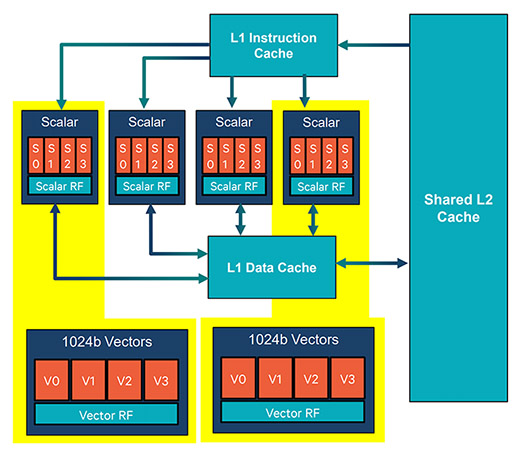
퀄컴이 헥사곤 685를 인공 지능의 기계 학습에 활용하는 것은 이 처리 장치의 구조를 볼 때 종전 CPU와 GPU보다 인공 지능 처리에 유리한 구조라고 판단한 때문이다. 퀄컴은 스냅드래곤 820의 헥사곤 680부터 고급 사진과 비디오, 가상 현실 및 컴퓨터 비전 처리를 위해 헥사곤 벡터 익스텐션(HVX) 아키텍처로 바꿨다. 헥사곤 680은 일반적인 ARM 프로세서에서 볼 수 있던 64비트 SIMD 네온 파이프라인보다 훨씬 넓은 4개의 1024비트 SIMD 파이프라인으로 1사이클에 최대 4096비트를 처리할 수 있고, 동시에 실행될 수 있는 여러 명령어를 포함한 VLIW 연산과 여러 HVX 컨텍스트를 처리하는 4개의 병렬 스칼라 스레드 구조를 갖췄다. 이후 스냅드래곤 835의 헥사곤 682와 스냅드래곤 845의 헥사곤 685는 이 구조를 개선하면서 기계 학습을 위해 정렬된 긴 벡터 데이터를 처리하는 데 활용하고 있는 것이다.
퀄컴은 헥사곤 685가 기계 학습 명령을 처리하는 성능에 대해선 구체적으로 밝히지 않았으나, DSP 뿐만 아니라 CPU와 GPU도 기계 학습에 관여하는 전반적인 처리 성능을 볼 때 이는 스냅드래곤 835 대비 3배 향상된 것이라고 말한다. 스냅드래곤 대비 3배의 수준이라는 것이 어떤 작업을 기준으로 보느냐는 것도 명확하지 않고, 초당 연산 회수에 대한 세부 내용도 없다 보니 화웨이, 구글, 애플의 신경망 코어와 비교할 때 상대적인 비교 우위 역시 아직은 확인하기 어려운 부분이다.
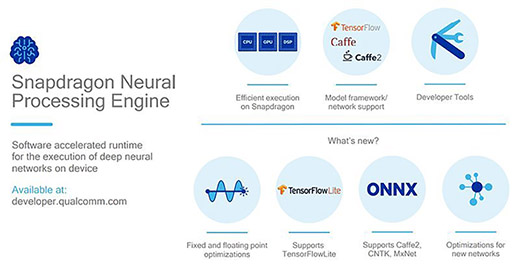
다만 신경망 구조를 가진 코어가 아닌 헥사곤 DSP에 다른 물리적인 구조를 추가하지 않고 관련 작업을 처리할 수 있도록 뉴럴 프로세싱 엔진(Neural Processing Engine)에서 처리할 수 있는 추론 API를 확장했다. 뉴럴 프로세싱 엔진은 스냅드래곤 프로세서에 존재하는 물리적인 요소가 아니라 추론을 위한 기계 학습 명령어를 스냅드래곤에서 처리할 수 있도록 최적화해주는 소프트웨어 도구다. 즉, 스냅드래곤에서 처리해야 할 기계 학습이 있다면 뉴럴 프로세싱 엔진을 거친 뒤 구조가 다른 스냅드래곤 프로세서의 CPU와 GPU, DSP가 모두 가동해 처리할 수 있도록 명령들을 정렬하고 결과를 얻을 수 있도록 해준다.
뉴럴 프로세싱 엔진을 거쳐 스냅드래곤 845에서 처리할 수 있는 추론 API는 텐서 플로를 비롯해 카페 및 카페2(Caffe 2) 등 기존 추론 API와 텐서 플로 라이트, ONNX 포맷도 처리할 수 있도록 보강했다. 또한 구글 안드로이드 8.0부터 지원하는 신경망 API도 지원한다.
퀄컴은 기존에 활용하던 여러 추론 API를 개발자가 프로세서에 맞춰 다시 개발할 필요 없이 뉴럴 프로세싱 엔진을 거쳐 스냅드래곤 800 시리즈 장치에서 적용할 수 있다는 것을 장점으로 꼽는다. 아이폰의 A11 바이오닉 프로세서에 있는 뉴럴 엔진이나 화웨이 기린 970에 탑재된 뉴럴 프로세싱 유닛, 구글의 비주얼 코어 등 신경망 코어들은 초기에 기존 추론 API를 활용하는 것이 아니라 각각 전용 개발을 요구하는 점에서 접근하기 어렵지만, 퀄컴은 좀더 쉽고 빠르게 접근할 수 있다는 것이다.
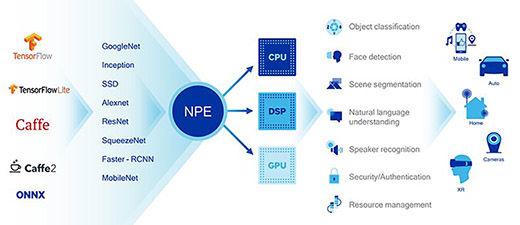
하지만 화웨이는 텐서 플로 및 텐서 플로 라이트, 카페 등 추론 API를 NPU에서 적용할 수 있는 개발자 도구를 공개했고, 안드로이드 8.1을 배포 중인 구글은 안드로이드 신경망 API(Android Neural Network API)계층에서 텐서 플로 라이트와 카페2, 그 밖의 추론 API를 곧바로 비주얼 코어 같은 신경망 코어를 통해 가속할 수 있도록 한 상태다. 그나마 퀄컴 스냅드래곤을 채택하는 스마트폰이나 장치 제조사가 많다는 점은 다른 제조사보다 관련 생태계 확장에 좀더 우위를 가질 만한 부분으로 보인다.
Be First to Comment